同前一篇,做个记录
源码repo
#Contents
| Level 21 | Level 22 | Level 23 | Level 24 | Level 25 |
| Level 26 | Level 27 | Level 28 | Level 29 | Level 30 |
| Level 31 | Level 32 | Level 33 |
#Level 21
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!Now for the level:
- We used to play this game when we were kids
- When I had no idea what to do, I looked backwards.
压缩包内有package.pack文件,先尝试16进制打开,看文件头会不会是常见的格式
1 | with open("assets/21/package.pack", 'rb') as f: |
789c000a40f5bf789c000740f8bf789c000640f9
78 9c“很像”是zlib文件的文件头 -> source
那用zlib解压data变量试试
1 | import zlib |
789c000740f8bf789c000640f9bf789c00ff3f00
又是78 9c,或许需要解压很多次咯
1 | import zlib |
425a683931415926535991e82f2b0076a97fffff
文件头变了,42 5a。变成了bzip压缩文件的文件头 -> source
1 | import zlib, bz2 |
808d96cbb572a70006587ada664f19ee846ba464
80 8d没搜到是哪种格式的文件头。对了,readme.txt中说过When I had no idea what to do, I looked backwards.
1 | import zlib, bz2 |
b'sgol ruoy ta kool'
得到的结果再倒过来念就是"look at your logs"。解压文件也会有日志产生吗?
又是不懂的东西了。搜了一圈发现,原来这里说的日志是要我记录下每次解压所用的方法2333
1 | import zlib, bz2 |
直接将logs变量打印出来完全看不出内容。所以我用Counter统计一下每个字符出现的次数,也许有点用
Counter({'*': 423, '@': 300, '#': 9})
出现次数与其他两个差距这么大,可能#在这里是分隔符的作用
1 | lines = "".join(logs).split("#") |
得到结果

进入下一题
其实,在if条件语句中,利用bytes格式进行判断是个更好的选择,能节省下很多不必要的计算。但是16进制更方便查询文件头,所以程序中也就没进行修改.
#Level 22
注释中写到 "or maybe white.gif would be mroe bright"。修改地址为.../white.gif,获得了一张黑色的图片。什么意思呢
也不是纯黑哦,放大好多倍后发现在图片正中有个灰色(或者说“不那么黑”)的像素不停跳动
这回的图片含有很多帧了,不像16题中的mozart.gif,只有一帧。
首先看一下每帧的图像模式
1 | from PIL import Image, ImageSequence |
P
RGB
RGB
哦?第一帧与其他帧还不一样,是八位像素的模式 -> source
不同的图像模式一定对应着不懂得像素值,这改怎么获取呢?pillow中有个ImageStat模块对图片进行一些数据上的计算,来试试看
1 | from PIL import Image, ImageSequence, ImageStat |
[(0, 8)]
[(0, 8), (0, 8), (0, 8)]
[(0, 8), (0, 8), (0, 8)]
[(0, 8), (0, 8), (0, 8)]
[(0, 8), (0, 8), (0, 8)]
...
OK,那我们要找的像素值一共有两种存在形式,8以及(8, 8, 8)。这回获取这些灰色像素的坐标就容易多了
1 | from PIL import Image, ImageSequence |
coords变量是个长度为133的二维列表,white.gif一共有133帧。应该已经获得了所有的坐标了。仔细看一下这些坐标,所有坐标值都在点(100, 100)周围两个像素内。哦对了,copper.html页面上的图片看上去应该是个方向操纵杆,或许这些坐标分别代表一个方向?
1 | newpic = Image.new("1", (1000, 100)) |
voila,下一题的地址~
#Level 23
一头黄牛,页面标题叫做what is this module?。源码中有注释
TODO: do you owe someone an apology? now it is a good time to
tell him that you are sorry. Please show good manners although
it has nothing to do with this level.
----------
it can't find it. this is an undocumented module.
'va gur snpr bs jung?'
还记得19关Leopold Mozart的肖像下方的“Now you should apologize”吗?试试用同样的方法表达一下歉意吧
尝试了几种说辞后,我发现这次说的是真的,确实和本关没有关系
目光转向剩下的内容
'va gur snpr bs jung' 应该是最重要的信息了。哦,页面标题叫做“What is this module?”熟悉Python的人应该都知道“The Zen of Python”这首诗,运行import this即可将这首诗显示出来。这里用到的模块名字就叫“this”,是个巧合吗?
打开python lib 文件夹下的 this.py,vscode里直接按住ctrl左键点击即可。诶,这首诗在源文件中并不是原样存储的
1 | s = """Gur Mra bs Clguba, ol Gvz Crgref |
需要先对所有字母进行ascii码平移才能解密这首诗。那,我们试试对'va gur snpr bs jung'进行相同的处理试试
1 | s = 'va gur snpr bs jung' |
in the face of what
谜面这么明显,到诗中找到那句话就可以了~
#Level 24
页面标题叫 “From top to bottom”。图片名为maze.png。
要用路径搜寻算法?学习一下,正好利用这个机会试一下BFS算法和DFS算法,(或许也试一下A*算法)。MIT OpenCourseWare有针对这两种算法的质量很高的公开课
放大几倍后可以发现maze.png最外圈只有两个黑色像素点,一个在右上角,一个在左下角。这两个像素大概率就是整个迷宫的入口和出口了。迷宫的“墙”是白色,“路”是黑色,emmm,和往常的迷宫有点不同哈哈哈
虽然作了这么多关python challenge已经比较熟悉pillow模块了,这关我还是用OpenCV嘞
首先,入口和出口得到坐标是必需的
1 | import cv2 |
639
1
那么两个点的坐标就分别是(0, 639)和(640, 1)了。假设右上角是入口,左下角是出口。
#BFS 算法
BFS算法中需要的FIFO队列可以通过Queue模块或collections模块中的deque类实现,最简单的python列表其实也可以满足要求
1 | import cv2 |
First 20 coordinates:
[(0, 639), (1, 639), (2, 639), (3, 639), (4, 639), (5, 639), (6, 639), (7, 639), (8, 639), (9, 639), (10, 639), (11, 639), (11, 638), (11, 637), (11, 636), (11, 635), (12, 635), (13, 635), (14, 635), (15, 635)]
Last 20 coordinates:
[(637, 9), (636, 9), (635, 9), (635, 8), (635, 7), (635, 6), (635, 5), (635, 4), (635, 3), (634, 3), (633, 3), (633, 2), (633, 1), (634, 1), (635, 1), (636, 1), (637, 1), (638, 1), (639, 1), (640, 1)]
结合maze.png原图,头尾的坐标点看上去是个合理的路径了。当然也可以输出更多的坐标点来验证。
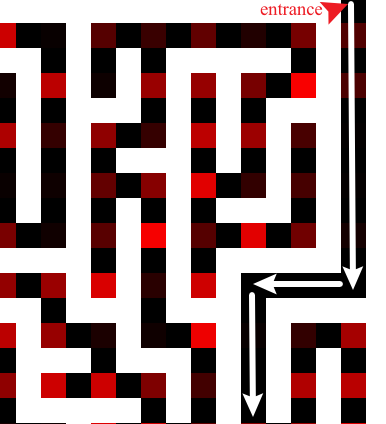

#DFS算法
1 | def DFS_sub(img: np.ndarray, current, entrance: np.array, queue: list, visited: dict): |
#那么,接下来呢?
说实话,接下来做什么我完全没头绪了。上网搜了一下,发现本题最重要的信息不是这些坐标,而是这些坐标点上像素的RGB值,准确来说是R值,因为所有点的B和G值都为0。每两个点中取一个非零值(都为零的话取零),然后就得到结果了。不过我没查到有关8075是zip文件的文件头的信息。
把上面最后一段代码改为如下
1 | path = DFS(img=img, entrance=entrance, exit=exit)[1:] # change the function name to use different methods |
得到的maze.zip文件中就有下一题的地址了,还有另一个压缩文件mybroken.zip目前还没用上。
#Level 25
网页标题:
Imagin how they sound
源码中的注释:Can you see the waves?
主图地址为lake1.jpg。它既然说“sound”,那改成音频文件扩展名试试,lake1.wav、lake1.mp3之类的。尝试几下就会发现lake1.wav是可以下载的文件,从文件名中也能看出来还会有一大堆音频文件,lake2、lake3……
1 | import requests |
一共获得了25个音频文件,主图lake1.jpg恰好是25个小块组成的拼图,那么要做的应该就是把这些音频文件转成图片然后拼在一起咯
那么,应该用音频中的什么信息生成图片呢?尝试了波形、频谱,输出都不像。没办法,又得搜一下了。
原来是要把每个音频文件直接通过bytes格式保存成音频文件……
好吧,给我再久我也想不到这个办法
1 | import wave |
每个音频文件参数都相同
_wave_params(nchannels=1, sampwidth=1, framerate=9600, nframes=10800, comptype='NONE', compname='not compressed')
从这些参数中能看出来,每个音频文件大概都包含10800个字节,一张3600个像素的图片恰好也包含10800个字节。
1 | from PIL import Image |
结果就在输出的图片中了
#Level 26
Be a man - Apologize!
源码中的注释只有一句:you've got his email.
Email,26道题以来见到的唯一一个邮箱在19关。所以并不是用修改请求头的方式道歉,而是应该写邮件道歉咯2333。然而,可能因为站点运行这么多年有些程序已经不运行了?我发了邮件但一直没接到回复……上网搜索这题的时候发现是应该接到一封回复的。会给一个md5加密后的值,用来处理[24关]的mybroken.zip
Never mind that.
Have you found my broken zip?
md5: bbb8b499a0eef99b52c7f13f4e78c24b
Can you believe what one mistake can lead to?
步骤很明显了,不断修改mybroken.zip文件,得到一个相同地md5加密结果
事实上,我用7-zip解压了mybroken.zip后里面的mybroken.gif就是完整的,虽然解压的时候提示了CRC failed。图中是单词“Speed”。我也不知道7-zip是怎么做到的,但是网上的一些解法中是提到这个图片是不完整的,需要修改mybroken.zip后才能完成显示出来。
它说了“one mistake”,那么应该是只有一个字节出现错误了呗。那就逐字节修改,然后看一下md5加密结果就行了
1 | import hashlib |
这回解压mybroken.zip就不会报CRC failed了。再结合页面上说的“I'm missing the boat”,答案就是speedboat了。
#Level 27
Between the tables.
图片带有链接,需要另一组用户名和密码才能访问。源码注释中:
did you say gif?
oh, and this is NOT a repeat of 14
主图地址zigzag.jpg,改成zigzag.gif,是一张灰度图。
回过头看看,自从23关以来我还没完全独立完成一道题过。题目是越来越难了,这题当然也不例外。
gif文件通常都是以P模式保存的,这样可以节约很多空间。P模式需要一个调色板(Palette)来显示图片。每个像素中所存储的信息为对应颜色在调色板中的位置。此题的关键就是图片zigzag.gif的调色板了
1 | from PIL import Image |
这个调色板中数值排列十分规律,每三个数值都完全一致。每组取一个值即可
下一步就是将像素中存储的信息转化为对应的颜色了
1 | from PIL import Image |
img_b first 20: d7d0cb0cfe3c8b4842bd7fb0ad46aacf27207e8e
img_b last 20: 7a5f0d5b95e3b20e6a0388bf05d439b8174efa64
result first 20: d0cb0cfe3c8b4842bd7fb0ad46aacf27207e8ea4
result last 20: 5f0d5b95e3b20e6a0388bf05d439b8174efa645d
看上去img_b和result两个变量中的信息有很多的重叠,除了首尾两个字节。
1 | print(len(img_b) == len(result)) |
True
False
好吧,虽然两个变量长度完全相同,但内容还是有很多不同的地方的。那,对比一下吧
1 | raw, img_b = raw[1:], img_b[:-1] |
b'BZh91AY&SY\xe0\xaaYF\x00\x17\x9a\x11\x80@'
b'\x99\xbdQ\x82\xf2\x89S\x04\x15E\x047 \x04\x95\xe4N\x9b\xd5\xa8'
第一个很明显是bzip压缩的内容了,另一个则毫无头绪
1 | clue1, clue2 = bytes(diff_raw), bytes(diff_b) |
获得了一大篇内容,其中一个是网址,其他的都是单词。利用python set去下重
1 | l1 = clue1.decode().split(' ') |
{'else', 'is', 'raise', 'pass', 'assert', 'while', "while'", 'yield', 'in', 'lambda', 'for', 'return', 'or', '../ring/bell.html', 'exec', 'def', 'if', 'break', 'continue', 'not', 'and', 'import', "b'../ring/bell.html", 'switch', 'class', 'except', 'global', 'del', 'repeat', 'from', 'elif', 'try', 'print', 'finally'}
../ring/bell.html就是主图超链接的网址,那么用户名和密码就应该在剩下的这些单词中了。问题是,到底是哪两个呢
把这些不同信息的位置记录下来,在对应位置进行标记,可以获得最重要的信息
1 | ... |

好了,那么接下来把python关键词去除掉就可以了
1 | clue1, clue2 = bytes(diff_raw), bytes(diff_b) |
repeat
exec
../ring/bell.html
switch
这道题需要修改一下了,python3删除了一部分关键词,原本应该只剩下两个单词的。接下来要做的也不难,找到在python2和python3中都不是关键词的两个单词就可以了。
可能要用到的信息:python2的关键词
#Level 28
Ring-Ring-Ring, say it out loud.
读起来有些像grin或者green。先试试grin.html
you are not happy - you are feeling sick.
好的,那么一定是green.html了
Yes, Green!
啊?就这一句,就没了?
回过头来仔细看一下主图bell.png,可以看到整张图上面有很多颜色略不同的条带。那信息应该藏在RGB的G值中咯
1 | import cv2 |
g1存储有307200个数值,仔细看一下,相邻两个数值的差值好像都是42/-42
对相邻的数值做减法,把42/-42都踢掉试一下
1 | import cv2 |
[119, -104, -111, 100, 117, 110, -110, 105, 116, -40, 41, -46, -115, 112, -108, 105, 116, 40, 41, 91, 48, -93, 32, -63]
有没有让你想起类似ascii码之类的?反正我有。
1 | print("".join(chr(abs(j)) for j in l)) |
whodunnit().split()[0] ?
做了什么?我最初以为是指站点,在About页面里可以看到,Nadav Samet创立的这个站点。试了一下,名和姓都不是答案。
诶,就差一步就独立解出这题了,这里指的是Python的创立者。555
#Level 29
这关很有趣。网页和源码中都没什么太有价值的东西。
如果你不看源码行数的话……
多数时间我都用dev tools查看源码。没有源码行数显示,没发现什么信息
不过,这么二十多关下来,我也习惯了用requests模块获取源码看一下了。这成了我完成这关的重要一步,哈哈哈
1 | import requests |
除了网页的内容之外,在源码后面有一大堆空行。终端中显示出来是看不出区别了
在guido.html页面里按ctrl+u。不同的浏览器快捷键可能有所不同。在microsoft edge dev中这个快捷键转入了view-source:http://www.pythonchallenge.com/pc/ring/guido.html页面,在这个页面里看源码清晰很多。
全选一下,就会发现,源码后面的空行长度各不相同。好了,这应该就是解题之关键了。
1 | import requests |
[66, 90, 104, 57, 49, 65, 89, 38, 83, 89, 217, 194, 112, 24, 0, 0, 4, 157, 128, 96, 128, 0, 0, 128, 32, 46, 47, 156, 32, 32, 0, 49, 76, 152, 153, 6, 70, 17, 50, 104, 100, 6, 106, 85, 100, 185, 158, 198, 24, 197, 146, 82, 72, 229, 90, 34, 1, 186, 167, 128, 127, 139, 185, 34, 156, 40, 72, 108, 225, 56, 12, 0, 0]
ascii码?
1 | msg = [chr(len(i)) for i in r.text.split("\n")[12:]] |
['B', 'Z', 'h', '9', '1', 'A', 'Y', '&', 'S', 'Y', 'Ù', 'Â', 'p', '\x18', '\x00', '\x00', '\x04', '\x9d', '\x80', '`', '\x80', '\x00', '\x00', '\x80', ' ', '.', '/', '\x9c', ' ', ' ', '\x00', '1', 'L', '\x98', '\x99', '\x06', 'F', '\x11', '2', 'h', 'd', '\x06', 'j', 'U', 'd', '¹', '\x9e', 'Æ', '\x18', 'Å', '\x92', 'R', 'H', 'å', 'Z', '"', '\x01', 'º', '§', '\x80', '\x7f', '\x8b', '¹', '"', '\x9c', '(', 'H', 'l', 'á', '8', '\x0c', '\x00', '\x00']
从前几个字符也能看出来是bzip压缩过的内容了
1 | import requests, bz2 |
b"Isn't it clear? I am yankeedoodle!"
哈哈,这道题有些运气成分在里面了,没遇到什么太大的困难。
#Level 30
从源码中可以看出来要访问yankeedoodle.cvs文件
下载下来粗略看一眼,都是0到1之间的“随机”数
1 | import numpy as np |
7367
尝试把这些数字当成一张图片来处理,首先需要知道图片该有多大,分解7367
1 | import math |
[[53, 139]]
图片大小只有一种可能了,53px*139px
1 | import cv2 |
输出糊成一片。交换高和宽的数值
1 | img.resize((width, height)) |
这下能看出图片内容了:n=str(x[i])[5]+str(x[i+1])[5]+str(x[i+2])[6]。没猜错的话,要做的就是把这些浮点数对应位置的数字提取出来咯
1 | with open("assets/yankeedoodle.csv", "r") as f: |
得到了一大篇数字,又是ascii码?
1 | info = [] |
So, you found the hidden message.
There is lots of room here for a long message, but we only need very little space to say "look at grandpa", so the rest is just garbage.
(还有一大堆乱码)
好了,那就是Grandpa了。
#Level 31
Where am I?
主图grandpa.jpg带有链接,可能是下一题的页面?需要另一组用户名和密码验证,进不去。源码中的注释为
short break, this ***REALLY*** has nothing to do with Python
那既然都这么说了,百度/谷歌/bing/yandex识图吧。搜索结果叫 Ko Samui (也称 Koh Samui),是泰国第二大岛屿。
尝试ko/samui、koh/samui、kosamui/thailand、kohsamui/thailand。好家伙试了四遍才试出来……
新页面上来就一句话“That was too easy. You are still on 31...”
好吧,那这页才是真正的第31关咯
页面标题:UFOs?
源码里什么信息都没有。哦不对,图片名字是个信息,"mandelbrot"。
好了,又是道完全没头绪的题目了,再去搜索一下吧
1 | def mandelbrot(size: tuple): |
这是本道题中生成mandelbrot set的方法,别问我各个参数的意义,hhh
1 | img = Image.open("assets/mandelbrot.gif") |
获取到的图片和原图mandelbrot.gif非常相像
1 | diff = [(a - b) for a, b in zip(img.getdata(), newimg.getdata()) if a != b] |
变量diff中的数值都为16/-16,一共1679个数据
将其改为1-bit图像,对1679进行因数分解就能知道图片大小只能为23px*73px。
1 | result = Image.new("1", (23, 73)) |
这样获得的图像就是于1974年送入太空的大名鼎鼎的Arecibo message
那么答案自然就是arecibo了
#Level 32
页面标题etch-a-scetch。看上去是要我们在页面上画点什么
源码中提到了warmup.txt,顾名思义,这只是开胃菜咯
比较简单,直接用arecibo.html就能徒手点出来哈哈哈

You want to go up? Let's scale this up then. Now get serious and solve this.
好了,这下子没法徒手完成了
必须要承认的是,我把这题想的太简单了,先停在这里吧,有些急事要做……
说起来很有意思,同事前两天正好在玩同样的一个游戏,所以我向他请教了一下这类游戏的解法。结果同事说他也刚开始玩,和我一样,硬解。不过他也告诉我说这游戏名字叫Nonogram,网上有很多在线的解答网站。
好了,对up.txt进行一些小修改,再结合在线解答网站的**亿点点**帮助,很快就得到了一条小蛇。
snake.html 404。答案是python.html……吗
1 | Congrats! You made it through to the smiling python. |
嗯,搜一下就知道了
#Level 33
终于到最后一关了。尽管上一关还没真正动手。我过完这一关就回头做一下,真的^o^。
图片名叫beer1.jpg,做了这么多关了,自然要试一下beer2.jpg。显示"no, png"。
好,那就是beer2.png了。
网页源码中的注释自然也不能忘记
1 | <!-- |
简单猜测着翻译一下:
去掉比较亮的像素点,调整为正方形图像
首先,确认一下beer2.png的图像模式
1 | from PIL import Image |
L
从Pillow文档中可以查到"L"表示八位黑白图像
去除比较亮的像素点,当图片恰好能调整成为正方形时输出图像
1 | from PIL import Image |
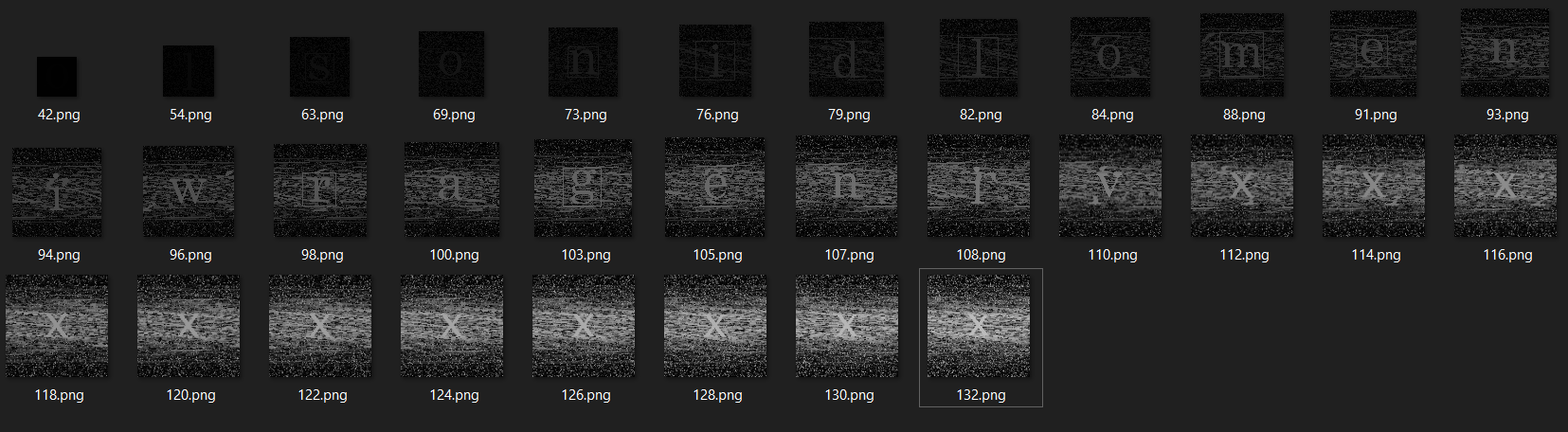
110.png之后的图像中出现了不一样的字母,不过不太清楚
1 | from PIL import Image |
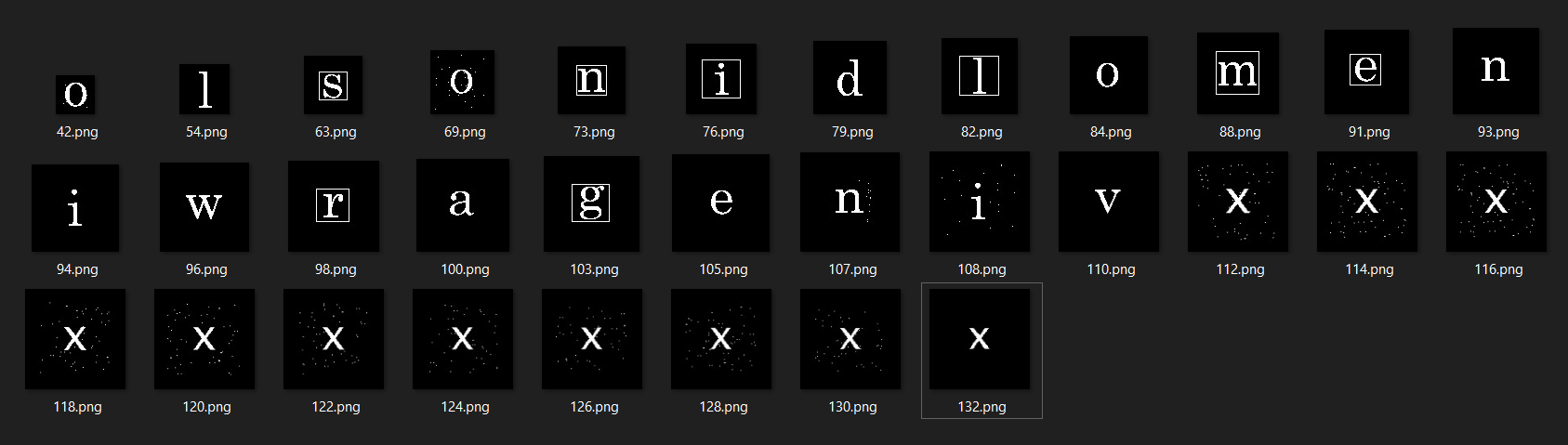
那么,带着框的字母应该能够组成本关的答案咯,修改地址为snilmerg.html,没用。
啊!字母的排列顺序应该与其出现顺序一致,换句话说,103.png比98.png先出现,那么字母g就应该在字母r之前,所以答案应该是gremlins.html
#结语
解谜这就告一段落啦!从这段解谜的过程中学到了很多有关图像处理、网络请求、文件结构方面的东西。真的推荐正在学习python甚至是精通python的朋友们试一下。
还有一件事,32关我会写一下的,过一阵的。^.^