Just some notes,http://www.pythonchallenge.com/
Complete source code here
#Contents
| Level 1 | Level 2 | Level 3 | Level 4 | Level 5 |
| Level 6 | Level 7 | Level 8 | Level 9 | Level 10 |
| Level 11 | Level 12 | Level 13 | Level 14 | Level 15 |
| Level 16 | Level 17 | Level 18 | Level 19 | Level 20 |
#Level 0
238=274877906944
Change the url to http://www.pythonchallenge.com/pc/def/274877906944.html,and there comes Level 1.
#Level 1
Obviously, by adding an offset to the ascii of each letter in the sentence you'll get the instruction.
1 | line = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj." |
The output
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
OK, apply to the url map, and the url for level 2 is here.
Noted that it mentioned str.maketrans() function, which is not how I solved the problem. So what does maketrans() do? Here is the official documentation. In short, it generates a translating method. str.translate() function then uses this method to translate a giving string. Now let's try this out.
1 | line = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj." |
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
OK, exactly what we expected.
#Level 2
It's evident that we should take a look at the source code of the page. There's a comment: find rare characters below.
For convenience, save all those charactors to assets/txt_for_2.txt, and find out the occurrence of each charactor.
1 | from collections import Counter |
Counter({')': 6186, '@': 6157, '(': 6154, ']': 6152, '#': 6115, '_': 6112, '[': 6108, '}': 6105, '%': 6104, '!': 6079, '+': 6066, '$': 6046, '{': 6046, '&': 6043, '*': 6034, '^': 6030, '\n': 1219, 'e': 1, 'q': 1, 'u': 1, 'a': 1, 'l': 1, 'i': 1, 't': 1, 'y': 1})
OK, combine the charactors only show up once, and there you get the url for next level.
#Level 3
Again, obviously, this level demands regx. Taking a look at the source code is a must. Save those charactors to assets/txt_for_3.txt and let's go for it.
1 | import re |
And the output is linkedlist, now change the url. The url for the next level is a little different, as it says.
#Level 4
Nothing on the page or in the source code. Click on the image, it leads us to a new page and says the next nothing is 44827.
Change the url to ...?nothing=44827. Oh, again, the next nothing is 45439. Seems that some http library like requests is needed.
1 | import requests |
Wait for a reasonable output.
#Level 5
pronounce it.
Go for source code. The image is called peakhell.jpg. And there's something didn't show up on the page.
1 | <peakhell src="banner.p"> |
Changing url to banner.p, there's a load of charactors making no sense at all.
Back to where we started, "pronounce it". There's a module called pickle which is for serializing and de-serializing.
1 | from urllib import request |
The output turns out to be a two-dimensional list. Take a glance at it. The numbers in the first three lines add up to 95. There's a possibility that the number is the occurrence of the charactor in front.
1 | for i in result: |
The output is
#Level 6
zip
Change the url to *.zip and we get a file channel.zip. Unzip it, there's a readme.txt. Well, it's similar to level 4.
1 | PATH = 'assets/channel/' |
NO, the program runs into an error. In the last file
collect the comments.
Now, what is a zip comment? Google it:
A comment is optional text information that is embedded in a Zip file. ->source
With 7zip, we can see the comment of each file. The lengths of those comments are the same, only one charactor. Now, let's have fun with the zip file. zipfile module is needed, of course.
1 | import zipfile |
Replace the url with hockey. It says it's in the air. look at the letters. Well, ya know what to do.
#Level 7
Just a picture, nothing in the source code. The information has to be in the picture, then.
Noted there's a horizontal line which does not fit the picture at all. By observing the line pixel by pixel with Snipaste, we can find out that the color turns different every 7-9 pixels.
1 | import cv2 |
offset = 7: [115, 109, 97, 114, 116, 32, 103, 117, 121, 44, 32, 121, 111, 117, 32, 109, 97, 100, 101, 32, 105, 116, 46, 32, 116, 104, 101, 32, 110, 101, 120, 116, 32, 108, 101, 118, 101, 108, 32, 105, 115, 32, 91, 49, 48, 53, 44, 32, 49, 49, 48, 44, 32, 49, 49, 54, 44, 32, 49, 48, 49, 44, 32, 49, 48, 51, 44, 32, 49, 49, 52, 44, 32, 49, 48, 53, 44, 32, 49, 49, 54, 44, 32, 49, 50, 49, 93]
offset = 8: [115, 109, 97, 114, 116, 103, 117, 121, 44, 32, 121, 111, 32, 109, 97, 100, 101, 32, 105, 46, 32, 116, 104, 101, 32, 110, 120, 116, 32, 108, 101, 118, 101, 32, 105, 115, 32, 91, 49, 48, 44, 32, 49, 49, 48, 44, 32, 49, 54, 44, 32, 49, 48, 49, 32, 49, 48, 51, 44, 32, 49, 52, 44, 32, 49, 48, 53, 44, 49, 49, 54, 44, 32, 49, 50, 93]
offset = 9: [115, 109, 97, 116, 32, 103, 121, 44, 32, 121, 117, 32, 109, 100, 101, 32, 105, 46, 32, 116, 101, 32, 110, 101, 116, 32, 108, 118, 101, 108, 32, 115, 32, 91, 48, 53, 44, 32, 49, 48, 44, 49, 49, 54, 44, 49, 48, 49, 32, 49, 48, 51, 32, 49, 49, 44, 32, 49, 48, 44, 32, 49, 54, 44, 32, 49, 49, 93]
Translate these numbers as ascii code
1 | s1 = [chr(i) for i in l1] |
offset = 7: smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]
offset = 8: smartguy, yo made i. the nxt leve is [10, 110, 16, 101 103, 14, 105,116, 12]
offset = 9: smat gy, yu mde i. te net lvel s [05, 10,116,101 103 11, 10, 16, 11]
It's obvious that result under offset=7 makes sense. Now do the same thing to the numbers in the result.
#level 8
There's a link on the body of the bee. And it leads us to a site which requires logging in. Source code! of course.
1 | un: 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084' |
un stands for user name, pw for password, of course. These charactors are compressed by bzip2. Let's de-compress it.
1 | import bz2 |
b'huge'
b'file'
#Level 9
The page is called connect the dots, and there lies an interesting comment, first+second=? followed by a bunch of numbers. Maybe these numbers are coordinates?
1 | import cv2 |
Fact is, we do not need the image good.jpg. A blank picture works just fine.
1 | img = np.zeros((512,512,3), np.uint8) |
There it comes.

The answer lies in cow/bull/ox/cattle. Take your shots.
#Level 10
There's a link on the body of the cow. It's a list which has no end, for now. a = [1, 11, 21, 1211, 111221,.
I didn't know what this list is. Google 1, 11, 21, 1211, 111221, it's called Look-and-say sequence. Now, we know what it is, the problem is simple.
1 | a = ['1'] |
And the url for the next level shows.
#Level 11
odd even, and just a picture. Obviously, we are gonna have fun with the picture.
Try splitting the picture by the odd/even of the sum of x,y of each pixel.
1 | import cv2 |
The url for the next level lies in the "even" picture.
#Level 12
dealing evil. What do you mean?
The picture is called evil1.jpg. Maybe there're pictures called evil2, evil3 maybe even evil4, evil5.
evil2.jpg, it says not jpg, _.gfx
What is a .gfx file? Google it!
The GFX file type is primarily associated with Cue Club Image File. ->source
Ah, it's also a image file.
Go on, evil3.jpg. OK, it says no more evils. The information has to be in the evil2.gfx and evil1.jpg then.
FYI: You need to try evil4 and evil5, for problems after.
Open evil2.gfx, and convert it directly to evil2.jpg
1 | with open("assets/evil2.gfx", "rb") as f: |
Well, it doesn't work.
OH, "dealing" cards. Maybe we should split the evil2.gfx into several files.
Try to split it into 2 files all the way to 5 files. And finally some visible image. The answers are in the pictures.
1 | with open("assets/evil2.gfx", "rb") as f: |
Wait, what does evil1.jpg do? Well, all the cards are 5, could be a hint I ignored...
#Level 13
Click on button 5, and we get a xml file.
To be honest, I know nothing about this problem. I had to look for solutions online. Here are something I learned during the search.
xml-rpc is a POST request in the form of xml. The response is also in the form of xml. There're xmlrpc.client and xmlrpc.server modules in python to perform these kinds of task. As the name indicates, xmlrpc.client is what we need for this problem.
1 | import xmlrpc.client |
First construct a ServerProxy subject, then use system.listMethods method to list all the methods this server provides.
1 | print(post.system.listMethods()) |
['phone', 'system.listMethods', 'system.methodHelp', 'system.methodSignature', 'system.multicall', 'system.getCapabilities']
Among these, phone seems like a unique method of this server, use system.methodHelp to display its description
1 | print(post.system.methodHelp("phone")) |
Returns the phone of a person
OK now, we've known which method to use. The only condition left is the person. According to some online solutions, there is some information in evil4.jpg. I was too naive to trust its saying. However, because the site was constructed a long while age, only IE browser could get access to this page. We can use curl to read the page. The output indicates this person should be "Bert".
So we "phone" Bert.
1 | print(post.phone("Bert")) |
555-ITALY
#Level 14
"Walk around", and a picture. Maybe this problem has something to do with circles or spirals. The bar(?) picture should be the picture that we should deal with.
Don't forget the comment of the page
remember: 100*100 = (100+99+99+98) + (...
Noted the information of this wire.png in DevTools:
Rendered size:100 × 100 px
Rendered aspect ratio:1∶1
Intrinsic size:10000 × 1 px
Intrinsic aspect ratio:10000∶1
File size:15.9 kB
Current source:http://www.pythonchallenge.com/pc/return/wire.png
Although it was displayed in the size of 100px*100px, the picture is actually in the size of 10000px*1px.
What is the equation then?
For example, here's a picture of 5px*5px. When you walk from the outside of it, and spirally inside, as shown below.

the "steps" you take until you make a turn is 5,4,4,3,3,2,2,1,1
Now, let's try 100px*100px, the equation can be deducted.
100*100 = 100+99+99+98+98+97+97+...+3+3+2+2+1+1
=(100+99+99+98)+(98+97+97+96)+...+(5+4+4+3)+(3+2+2+1)+1
So, the solution is to put every pixel of wire.png into a 100px*100px image "spirally".
1 | import cv2 |
Voila~. try cat.html. Oh, he's Uzi.
#Level 15
I'm gonna say it out directly. The musician Mozart.
Why? Look at the comment.
todo: buy flowers for tomorrow
So I searched for celebrities born in Jan 27th. And the first result is WOLFGANG AMADEUS MOZART.
Now, although having solved the problem, we're supposed to analyze the problem as well.
Jan 27th has to be a major day. Look at the bottom-right corner, there're 29 days in Feb that year. So the year 1XX6 is a leap year, Jan 1 that year is a Thursday. What's more
he ain't the youngest, he is the second
Then we're looking at the second nearest leap year ends with number 6.
1 | import calendar |
#Level 16
Let me get this straight
Seems that we should align these purple blocks in a straight line? If you observe the image with Snipaste, you are gonna find out there's only one purple block in each line, and each block consists of exactly 5 pixels.
Well, opencv module can't deal with .gif file. I had to spend some time learning the pillow module.
First we need to find out where these blocks situated in each line. The way to do it is to find five consecutive pixels with the same value.
1 | from PIL import Image |
195
The value we're looking for is 195. Then we crop all the pixels in front and put them behind.
1 | from PIL import Image |
What is the answer?
#Level 17
The bottom-left corner seems familiar. Yeah, it's the picture of level 4. So we're supposed to use http request modules for this one?
Cookies, what's in the cookies of this page?
you%20should%20have%20followed%20busynothing...
OK, we should replace the url ...?busynothing=12345 then.
Well, not exactly. All we got is a that's it. That's probably the end point of the request session. Maybe we should look at the cookies during this session as well?
1 | import re |
BZh91AY%26SY%94%3A%E2I%00%00%21%19%80P%81%11%00%AFg%9E%A0%20%00hE%3DM%B5%23%D0%D4%D1%E2%8D%06%A9%FA%26S%D4%D3%21%A1%EAi7h%9B%9A%2B%BF%60%22%C5WX%E1%ADL%80%E8V%3C%C6%A8%DBH%2632%18%A8x%01%08%21%8DS%0B%C8%AF%96KO%CA2%B0%F1%BD%1Du%A0%86%05%92s%B0%92%C4Bc%F1w%24S%85%09%09C%AE%24%90
The beginning seems like the charactors in level 8, ignoring the encoding.
1 | line = urllib.parse.unquote_to_bytes(cookies) |
b'BZh91AY&SY\x94:\xe2I\x00\x00!\x19\x80P\x81\x11\x00\xafg\x9e\xa0 \x00hE=M\xb5#\xd0\xd4\xd1\xe2\x8d\x06\xa9\xfa&S\xd4\xd3!\xa1\xeai7h\x9b\x9a+\xbf`"\xc5WX\xe1\xadL\x80\xe8V<\xc6\xa8\xdbH&32\x18\xa8x\x01\x08!\x8dS\x0b\xc8\xaf\x96KO\xca2\xb0\xf1\xbd\x1du\xa0\x86\x05\x92s\xb0\x92\xc4Bc\xf1w$S\x85\t\tC\xae$\x90'
Now, it looks exactly the same as bzip2 compressed content.
1 | print(bz2.decompress(line).decode("utf-8")) |
is it the 26th already? call his father and inform him that "the flowers are on their way". he'll understand.
call his father, and today is 26th. We are probably looking for Mozart's father. Google it! He's Leopold. Then call should be the phone method in level 13.
1 | import xmlrpc.client |
555-VIOLIN
Replace the url with .../violin.html.
no! i mean yes! but ../stuff/violin.php.
Go on. Well, the page is called it's me. What do you want? The content of the page is a portrait of Leopold Mozart. It's obvious that we should communicate with him then. Try modifying the cookies of the page.
1 | import requests |
And we get the result of
1 | <html> |
So, balloons. Oh, replace the url for level 17 rather than the url for the portrait.
#Level 18
Can you tell the difference?
One is darker?
it is more obvious that what you might think
OK, if you say so. Try luminance/brightness. There's nothing different in brightness.html. However the comment has changed a bit.
maybe consider deltas.gz
Replace the url. A deltas.gz file is downloaded then. We need gzip module then.
1 | import gzip |
A interesting output is here. There're two columns. Maybe we should find out the difference of these two columns. We need difflib module
1 | import gzip, difflib |
l1: ['89 50 4e 47 0d 0a 1a 0a ...]
l2: ['89 50 4e 47 0d 0a 1a 0a ...]
common: ['89 50 4e 47 0d 0a 1a 0a ...]
If you are familiar with the file structure of png files, you know what to do.
The first eight bytes of the result is the signature of a png file. ->source
Now we save the results in corresponding png files. The url, username and password lies right there.
1 | with open('assets/lvl18_1.png', 'wb') as f1: |
#Level 19
A map of India, and a email in the comment.
According to the email, we're supposed to get a audio with base64 encoding.
1 | import base64 |
All we can hear is
Sorry!
Try sorry.html
- "what are you apologizing for?"
Doesn't seem right. There has to be something we're missing.
I didn't know much of audios. This happens to be a brilliant chance to learn about wave module.
1 | import wave |
_wave_params(nchannels=1, sampwidth=2, framerate=11025, nframes=55788, comptype='NONE', compname='not compressed')
The information of the audio is clear as it says.
Noted the color in the map is reversed. Ocean is usually in blue and continent in yellow. Let's try reversing the audio.
1 | import wave |
Nothing we can hear in the result. Maybe reverse every frame of the audio.
1 | import wave |
"you are an idiot~ ah, ah, ah, ah ...
try idiot.html. Oh, it's Leopold. He says, "Now you should apologize..." and gives the link to the next level.
OK, We have it.
#Level 20
Well, I have no idea what to do. Again, I learned something during searching online.
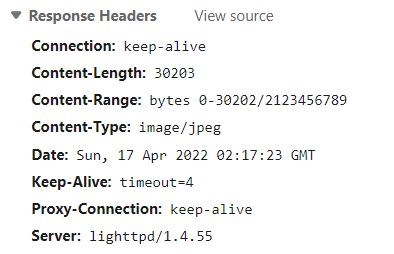
The picture above are the response headers of unreal.jpg. Now if we modify the Range value in the request headers, we'll get access to files of other range.
It's clear that between 0 and 30202 bytes lies unreal.jpg. Let's go on to the next section. Set Range value to bytes=30203-
1 | import requests, base64 |
{'Connection': 'close', 'Content-Length': '34', 'Content-Range': 'bytes 30203-30236/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 10:22:00 GMT', 'Server': 'lighttpd/1.4.55'}
Why don't you respect my privacy?
Go on.
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=30237-'} |
{'Connection': 'close', 'Content-Length': '47', 'Content-Range': 'bytes 30237-30283/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 10:55:42 GMT', 'Server': 'lighttpd/1.4.55'}
we can go on in this way for really long time.
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=30284-'} |
{'Connection': 'close', 'Content-Length': '11', 'Content-Range': 'bytes 30284-30294/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 11:07:43 GMT', 'Server': 'lighttpd/1.4.55'}
stop this!
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=30295-'} |
{'Connection': 'close', 'Content-Length': '18', 'Content-Range': 'bytes 30295-30312/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 14:22:22 GMT', 'Server': 'lighttpd/1.4.55'}
invader! invader!
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=30313-'} |
{'Connection': 'close', 'Content-Length': '34', 'Content-Range': 'bytes 30313-30346/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 14:23:12 GMT', 'Server': 'lighttpd/1.4.55'}
ok, invader. you are inside now.
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=30347-'} |
{'Connection': 'close', 'Content-Type': 'text/html; charset=UTF-8', 'Date': 'Mon, 18 Apr 2022 14:23:50 GMT', 'Server': 'lighttpd/1.4.55', 'Content-Length': '0'}
Nothing here. Maybe we should look for the final section.
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=2123456879-'} |
{'Connection': 'close', 'Content-Length': '45', 'Content-Range': 'bytes 2123456744-2123456788/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 14:25:37 GMT', 'Server': 'lighttpd/1.4.55'}
esrever ni emankcin wen ruoy si drowssap eht
Reverse the output.
the password is your new nickname in reverse
"nickname" should be the "invader" mentioned before. Hence the password should be redavni.
Go forward.
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=2123456743-'} |
{'Connection': 'close', 'Content-Length': '32', 'Content-Range': 'bytes 2123456712-2123456743/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 14:26:54 GMT', 'Server': 'lighttpd/1.4.55'}
and it is hiding at 1152983631.
The required Range value is here.
1 | headers = {'Authorization': f"Basic {cred.decode()}", 'Range':'bytes=1152983631-'} |
The output was too much. Let's take a look at the first 20 bytes of the output. The signature of file is always hiding there.
1 | print(r.content[:20]) |
{'Connection': 'close', 'Content-Length': '239733', 'Content-Range': 'bytes 1152983631-1153223363/2123456789', 'Content-Transfer-Encoding': 'binary', 'Content-Type': 'application/octet-stream', 'Date': 'Mon, 18 Apr 2022 14:30:03 GMT', 'Server': 'lighttpd/1.4.55'}
b'PK\x03\x04\x14\x00\t\x00\x08\x00;\xa7\xaa2\xac\xe5f\x14\xa9\x00'
The PK\x03\x04 is the signature of a zip file. ->source
Then we should save the output to a zip file and try to unzip it.
1 | with open('assets/20.zip', 'wb') as f: |
There's a readme.txt. OK, we are in level 21 now.