Again, just some notes
Complete source code here
#Contents
| Level 21 | Level 22 | Level 23 | Level 24 | Level 25 |
| Level 26 | Level 27 | Level 28 | Level 29 | Level 30 |
| Level 31 | Level 32 | Level 33 |
#Level 21
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!Now for the level:
- We used to play this game when we were kids
- When I had no idea what to do, I looked backwards.
There's this package.pack file inside the zip. First open it in HEX, maybe the file header is familiar.
1 | with open("assets/21/package.pack", 'rb') as f: |
789c000a40f5bf789c000740f8bf789c000640f9
78 9c is very likely file header of a zlib file. -> source
Now decompress the data variable with zlib.
1 | import zlib |
789c000740f8bf789c000640f9bf789c00ff3f00
Again, 78 9c. Maybe it's a file compressed multiple times.
1 | import zlib |
425a683931415926535991e82f2b0076a97fffff
Now, 42 5a. It's bzip compressed file. -> source
1 | import zlib, bz2 |
808d96cbb572a70006587ada664f19ee846ba464
80 8d doesn't seem like any file header. Oh right, it said When I had no idea what to do, I looked backwards.
1 | import zlib, bz2 |
b'sgol ruoy ta kool'
The output is "look at your logs" in reverse. Logs, what are logs when decompressing?
I had to search for this online. Turns out, here the "logs" means that you're supposed to record every decompression. hahaha
1 | import zlib, bz2 |
What was stored in the logs variable made no sense at all. So I used Counter to display the occurence of each charactor. Could be helpful, I thought.
Counter({'*': 423, '@': 300, '#': 9})
Seems charactor # is the separator.
1 | lines = "".join(logs).split("#") |
The output looks like this.

There you have it~
Well, as a matter of fact, it's better to use bytes format for if...elif...else conditional execution. And it saves a load of computing as well. For example the bytes format of 789c should be b'x\x9c'. HEX format did help with searching for what file headers should look like, though.
#Level 22
Woo, what a week! Now back to the challenge
The comment says "or maybe white.gif would be more bright". Change the url to .../white.gif. It's a black image.
Well, not exactly. With zooming in several times, a grey (or "not that black") pixel around the center of the image can be noticed.
And the image is actually a gif file with multiple frames, unlike mozart.gif from level 16, which, on the contrary, contains only 1 frame.
First we need to know the modes of the frames.
1 | from PIL import Image, ImageSequence |
P
RGB
RGB
...
There you have it. The first frame is a picture of 8-bit mode. -> source And the rest of it, all RGB mode
So how do we find the "grey pixels" when the frames are in different modes? There's a ImageStat Module which can be use to calculate various statistics of a picture. Let's try it out.
1 | from PIL import Image, ImageSequence, ImageStat |
[(0, 8)]
[(0, 8), (0, 8), (0, 8)]
[(0, 8), (0, 8), (0, 8)]
[(0, 8), (0, 8), (0, 8)]
[(0, 8), (0, 8), (0, 8)]
...
So the values of "grey pixels" come in two different ways, 8 and (8, 8, 8). Now let's get the coordinates of the "grey pixels".
1 | from PIL import Image, ImageSequence |
Variable coords is a two dimensional list, and its length is 133. The white.gif itself contains 133 frames as well. Seems we've gotten all the coordinates. Now let's take a deep look at the list.
All the values are within 2px distance to (100, 100). And value (100, 100) shows up relatively fewer times. Oh, don't forget about the picture in copper.html, it's something like a joystick. Maybe the coordinates represent directions.
1 | newpic = Image.new("1", (1000, 100)) |
And now we get the url for the next level.
#Level 23
A bull. Page title is what is this module?. And some text in the source code.
TODO: do you owe someone an apology? now it is a good time to
tell him that you are sorry. Please show good manners although
it has nothing to do with this level.
----------
it can't find it. this is an undocumented module.
'va gur snpr bs jung?'
Remember? In the end of level 19, we get a portrait of Leopold Mozart. And he says, "Now you should apologize". Maybe now is the time we say sorry.
Well, after trying for some times, I realized that it's being serious this time. It does have nothing to do with this level.
So let's focus on what's left here.
Seems that 'va gur snpr bs jung' should be a instruction. "What is this module?" If you are familiar with python, you'll know there's a famous poem called "The Zen of Python". You can get the poem simply by running import this. Here the module name is exactly "this". Coincidence?
And if you open this.py which is in the python lib folder. You'll see the poem itself is not stored as it shows.
1 | s = """Gur Mra bs Clguba, ol Gvz Crgref |
It requires shifting the ascii value of a letter to translate. Now we apply the same method to 'va gur snpr bs jung'
1 | s = 'va gur snpr bs jung' |
in the face of what
The answer is in the poem. Find it yourself~
#Level 24
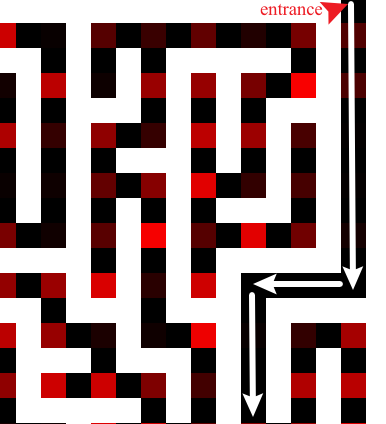
Page title is "From top to bottom". And the picture name is maze.png.
Path finding? A perfect chance to try BFS and DFS algorithm (maybe A* as well). If you know nothing about these two algorithm, MIT OpenCourseWare provided great lessons for both BFS and DFS algorithm.
Zoom in maze.png a few times. there're only 2 black pixels in the outer circle. One is on the upper right corner, the other lower left. It's very likely that theses 2 pixels are entrance and exit. White pixels being walls, feels a little different from usual.
Evem though I've become familiar with pillow recently, I am still gonna use opencv this time. lol.
First, we need the coordinates of entrance and exit.
1 | import cv2 |
639
1
Therefore the coordinates are (0, 639) and (640, 1). Let's just assume the entrance is the former one and exit the latter.
#BFS Algorithm
As for the FIFO queue used in the BFS algorithm, either Queue Module or deque class in collections module works just fine. Even a simple python list class would do the work as well.
1 | import cv2 |
First 20 coordinates:
[(0, 639), (1, 639), (2, 639), (3, 639), (4, 639), (5, 639), (6, 639), (7, 639), (8, 639), (9, 639), (10, 639), (11, 639), (11, 638), (11, 637), (11, 636), (11, 635), (12, 635), (13, 635), (14, 635), (15, 635)]
Last 20 coordinates:
[(637, 9), (636, 9), (635, 9), (635, 8), (635, 7), (635, 6), (635, 5), (635, 4), (635, 3), (634, 3), (633, 3), (633, 2), (633, 1), (634, 1), (635, 1), (636, 1), (637, 1), (638, 1), (639, 1), (640, 1)]
Combined with maze.png, these coordinates seems like a valid path. You can print out more coordinates to inspect.

#DFS Algorithm
1 | def DFS_sub(img: np.ndarray, current, entrance: np.array, queue: list, visited: dict): |
#What's next?
To be honest, I had no idea what to do next. So I did some search online. Turns out what really needed is not the coordinates, it's the RGB value of these pixels. To be accurate, the R(ed) value. Take 1 non-zero value in consective 2 pixels (if both are 0, then take 0), save the values in bytes format to a zip file, and voila. I didn't find information about 8075 being file header of a zip file, though.
Replace the last part of the code above with below:
1 | path = DFS(img=img, entrance=entrance, exit=exit)[1:] # change the function name to use different methods |
Inside the maze.zip file just created lies the url for the next level, with another zip file mybroken.zip which has not been used yet.
#Level 25
Page title:
Imagine how they sound
Inside the source code:can you see the waves?
Open the picture in a new tab. The url of the picture is lake1.jpg. "Sound" it says. Replace the url, maybe with lake1.wav or lake1.mp3 or other audio file extensions. Fact is, lake1.wav is a valid file we can download. Judging from the file name, there has to be a whole lot of audio files, such as lake2, lake3, etc.
1 | import requests |
There're in total 25 wav files. lake1.jpg is a jigsaw with exactly 25 pieces. Seems we are supposed to get 25 small pictures out of these wav files and put them together into a bigger picture.
So what information should we extract from them? I tried the waveforms, spectrums of the files. Nothing seems rational. Again, some online search.
Save each wav file into a image object, in bytes format. That's how it should be.
Well, I never thought about this.
Let's dive in.
1 | import wave |
All 25 files share the same parameters.
_wave_params(nchannels=1, sampwidth=1, framerate=9600, nframes=10800, comptype='NONE', compname='not compressed')
Judging from the parameters, each file contains proximately 10800 bytes, which is also size of a image consists of 3600 pixels.
1 | from PIL import Image |
And the answer is in the output.
#Level 26
Be a man - Apologize!
In the source code: you've got his email.
Email. The only email ever was in level 19. So we are supposed to write a email rather than modifying the request headers then. However, maybe the site has lost some functions over the years. The email I wrote never got a reply. When searching for informations, I found that a reply WAS supposed to appear, inside which a md5 thumbprint was offered to help dealing with the mybroken.zip in level 24.
Never mind that.
Have you found my broken zip?
md5: bbb8b499a0eef99b52c7f13f4e78c24b
Can you believe what one mistake can lead to?
It's clear that we should do some modification to mybroken.zip to get the same md5 thumbprint.
As a matter of fact, if you extract files from mybroken.zip using 7-zip, the mybroken.gif inside is completely visiable, in spite of a CRC failed problem. It's "Speed". I don't know about the details of how 7-zip managed to do this. But according to other solutions, only half of the image could be seen.
It says "one mistake". Only one byte of data is incorrect, then. Simply modify every byte of data and check the md5 thumbprint would do the trick.
1 | import hashlib |
Now the new zip file has no CRC problem. Conbined with "I'm missing the boat", the answer should be speedboat.
#Level 27
Between the tables.
The picture lead to a page which requires a new set of username and password. Inside the source code:
did you say gif?
oh, and this is NOT a repeat of 14
The url of the picture is zigzag.jpg. Change it to zigzag.gif, and we get a greyscale image.
Gee, I haven't work out a problem totally on my own since level 23. It's getting harder and harder for me to get the hints. Well, no surprises for this level.
Most of the gif files are in "P" mode. It's a good way to save space. A color palette is required so as to display a "P" mode image. The value stored in each pixels are a pointer to a color in the palette. Here the key to solve to problem is the color palette.
1 | from PIL import Image |
The arrangement of values in this palette is regular. Every consective three values are the same. What we need is only one of three same values.
Next thing to do is translate the pixel value to its color using palette.
1 | from PIL import Image |
img_b first 20: d7d0cb0cfe3c8b4842bd7fb0ad46aacf27207e8e
img_b last 20: 7a5f0d5b95e3b20e6a0388bf05d439b8174efa64
result first 20: d0cb0cfe3c8b4842bd7fb0ad46aacf27207e8ea4
result last 20: 5f0d5b95e3b20e6a0388bf05d439b8174efa645d
Seems that the first 20 bytes of variable result and variable img_b are identical, except for the first byte of img_b and last byte of relsult. Are they the same all the way?
1 | print(len(img_b) == len(result)) |
True
False
Turns out that these two variables are identical in lenth. The content we are looking at, on the other hand, are different.
Now let's compare the contents.
1 | raw, img_b = raw[1:], img_b[:-1] |
b'BZh91AY&SY\xe0\xaaYF\x00\x17\x9a\x11\x80@'
b'\x99\xbdQ\x82\xf2\x89S\x04\x15E\x047 \x04\x95\xe4N\x9b\xd5\xa8'
The first one is a bzip compressed content obviously. The other one, no clue.
1 | clue1, clue2 = bytes(diff_raw), bytes(diff_b) |
It's a bunch of information, one is a url, others are just words. Use set class to remove redundant words.
1 | l1 = clue1.decode().split(' ') |
{'else', 'is', 'raise', 'pass', 'assert', 'while', "while'", 'yield', 'in', 'lambda', 'for', 'return', 'or', '../ring/bell.html', 'exec', 'def', 'if', 'break', 'continue', 'not', 'and', 'import', "b'../ring/bell.html", 'switch', 'class', 'except', 'global', 'del', 'repeat', 'from', 'elif', 'try', 'print', 'finally'}
../ring/bell.html is the exact url that main picture of this level pointing at. That way, the username and password should be in the set as well. Question is, which ones?
If we take down the position of these differences, and make a image and change theses positions, we'll get a picture as follows.
1 | ... |

Now what's left to do is just filter python keywords outta that set earlier.
1 | clue1, clue2 = bytes(diff_raw), bytes(diff_b) |
repeat
exec
../ring/bell.html
switch
Apparently, this level is a little out of date. Some keywords being removed in python3 could be a reason. There should be only two words left alongside a url. So, which words are not keywords in both python2 and python3? It's simple now.
Useful link: keywords in python2
#Level 28
Ring-Ring-Ring, say it out loud.
Sounds like grin or green? First try grin.html.
you are not happy - you are feeling sick.
OK, then it has to be green.html.
Yes, Green!
What, nothing?
If you take a deeper look at the main picture bell.png, there're some "bands" in the picture. Maybe it has something to do with the G value.
1 | import cv2 |
Variable g1 stores 307200 values. And if you take a deep look at it, the differences of most consective two values are 42/-42.
Do the subtraction, filter out the values 42/-42.
1 | import cv2 |
[119, -104, -111, 100, 117, 110, -110, 105, 116, -40, 41, -46, -115, 112, -108, 105, 116, 40, 41, 91, 48, -93, 32, -63]
Does it remind you of something like ascii code? Well, it does for me.
1 | print("".join(chr(abs(j)) for j in l)) |
whodunnit().split()[0] ?
Whodun-WHAT? First I thought it's referring to the site. In About Page of python challenge I found the site was written by Nadav Samet. Not correct.
I was so so close to solving the problem totally on my own, except for a final kick. It is referring to the creator of Python!!
#Level 29
An interesting level. Nothing useful in both web page and source code.
Well, if there're no line numbers.
I use dev tools to view the source code mostly. There's nothing interesting in the source code that way.
However, I've come to loving using requests module to view the source code recently. That's where "magic" happens. lol
1 | import requests |
There're some blank lines in the end. You can't tell any differences between these lines when they are displayed in a terminal, though.
Press ctrl+u in guido.html. For other web broswers, the shortcut could be different. In microsoft edge dev, we enter a page view-source:http://www.pythonchallenge.com/pc/ring/guido.html. The source code are displayed much distinctly.
Select all, you'll see the length of these blank lines are different. Yeah, we got the key!
1 | import requests |
[66, 90, 104, 57, 49, 65, 89, 38, 83, 89, 217, 194, 112, 24, 0, 0, 4, 157, 128, 96, 128, 0, 0, 128, 32, 46, 47, 156, 32, 32, 0, 49, 76, 152, 153, 6, 70, 17, 50, 104, 100, 6, 106, 85, 100, 185, 158, 198, 24, 197, 146, 82, 72, 229, 90, 34, 1, 186, 167, 128, 127, 139, 185, 34, 156, 40, 72, 108, 225, 56, 12, 0, 0]
Ascii code?
1 | msg = [chr(len(i)) for i in r.text.split("\n")[12:]] |
['B', 'Z', 'h', '9', '1', 'A', 'Y', '&', 'S', 'Y', 'Ù', 'Â', 'p', '\x18', '\x00', '\x00', '\x04', '\x9d', '\x80', '`', '\x80', '\x00', '\x00', '\x80', ' ', '.', '/', '\x9c', ' ', ' ', '\x00', '1', 'L', '\x98', '\x99', '\x06', 'F', '\x11', '2', 'h', 'd', '\x06', 'j', 'U', 'd', '¹', '\x9e', 'Æ', '\x18', 'Å', '\x92', 'R', 'H', 'å', 'Z', '"', '\x01', 'º', '§', '\x80', '\x7f', '\x8b', '¹', '"', '\x9c', '(', 'H', 'l', 'á', '8', '\x0c', '\x00', '\x00']
It's pretty clear now. Bzip compressed content.
1 | import requests, bz2 |
b"Isn't it clear? I am yankeedoodle!"
Well, I was lucky this time. Didn't run into much trouble.
#Level 30
Source code has made it clear that we should look at yankeedoodle.csv.
In it are some "random" values between 1 and 0, on first glimpse.
1 | import numpy as np |
7367
What if we regard these values as a picture? First we need to find the factors of 7367
1 | import math |
[[53, 139]]
There's only one possibility then. The image has to be 53px*139px.
1 | import cv2 |
The output is a total mess. Switch the value of height and width.
1 | img.resize((width, height)) |
This time the output reads n=str(x[i])[5]+str(x[i+1])[5]+str(x[i+2])[6]. We are supposed to transform the float numbers into some string, if I'm right.
1 | with open("assets/yankeedoodle.csv", "r") as f: |
The output is a bunch of numbers. Again, ascii code.
1 | info = [] |
So, you found the hidden message.
There is lots of room here for a long message, but we only need very little space to say "look at grandpa", so the rest is just garbage.
(some unintelligible code)
Grandpa it is.
#Level 31
Where am I?
Main picture grandpa.jpg leads to another page, possibly for the next level. It requires another set of username and password to authenticate. The comment in the source code says
short break, this ***REALLY*** has nothing to do with Python
OK, if you say so. Google the image. It's Ko Samui (or Koh Samui), the second largest island in Thailand.
ko/samui, koh/samui, kosamui/thailand, kohsamui/thailand. Damn, finally, after four trials.
The new page reads "That was too easy. You are still on 31..."
OK, this page seems to be the real level 31.
Page title: UFOs?
The image name is interesting, "mandelbrot". This video explains it in detail, and helps a lot with understanding mandelbrot set.
Well, it's not enough just understand what a mandelbrot set is. At least, for me. I had no idea what to do next. Again, I looked for solutions online.
1 | def mandelbrot(size: tuple): |
This is how mandelbrot set should be like for this level. Don't ask me anything about the value of the z's and c's. LOL
1 | img = Image.open("assets/mandelbrot.gif") |
The image we get in this step looks pretty similiar to the mandelbrot.gif file.
1 | diff = [(a - b) for a, b in zip(img.getdata(), newimg.getdata()) if a != b] |
The values in diff are all 16/-16. And there're 1679 values in it.
Convert the variable to a 1-bit picture. The size has to be 23*73. These are the only set of factors of 1679.
1 | result = Image.new("1", (23, 73)) |
The image we get this time is the famous Arecibo message, which was sent into universe in 1974.
The answer, by the way ,is arecibo.
#Level 32
Page title is etch-a-scetch. Seems that we're to draw something in the page
A warmup.txt was mentioned in the source code.
This is pretty simple. We can solve it using the page arecibo.html

up.html then.
You want to go up? Let's scale this up then. Now get serious and solve this.
Now it's so much harder that we're not supposed to do it by hand.
It's harder than I thought. I'll pause here. Got something else urgent to do...
Funny story. A colleague played the exact same game the other day. So I turned to him for advice on how to solve this kind of problems. The game is called nonogram. And there're plenty of online solvers. He himself solves the problem just like I did.
With some adjustment to the up.txt and *some* help of an online nonogram solver, a snake is shown on the screen pretty soon.
Try snake.html. No good. python.html, yes.
1 | Congrats! You made it through to the smiling python. |
Well, just google it.
#Level 33
We're finally at the gate of the last problem, even though I did nothing about level 32. I'm gonna turn back to it, I promise.
Picture name beer1.jpg. Ring a bell? Of course, try beer2.jpg. It says "no, png".
So beer2.png then.
Source code contains some hints as well.
1 | <!-- |
A little translation, I guess:
Remove the brighter pixels, resize to a square image
First, we gotta know the mode of beer2.png
1 | from PIL import Image |
L
"L", is (8-bit pixels, black and white) according to pillow documentation.
Now remove the brighter pixels, and save the image only when the picture can be resized into squares.
1 | from PIL import Image |
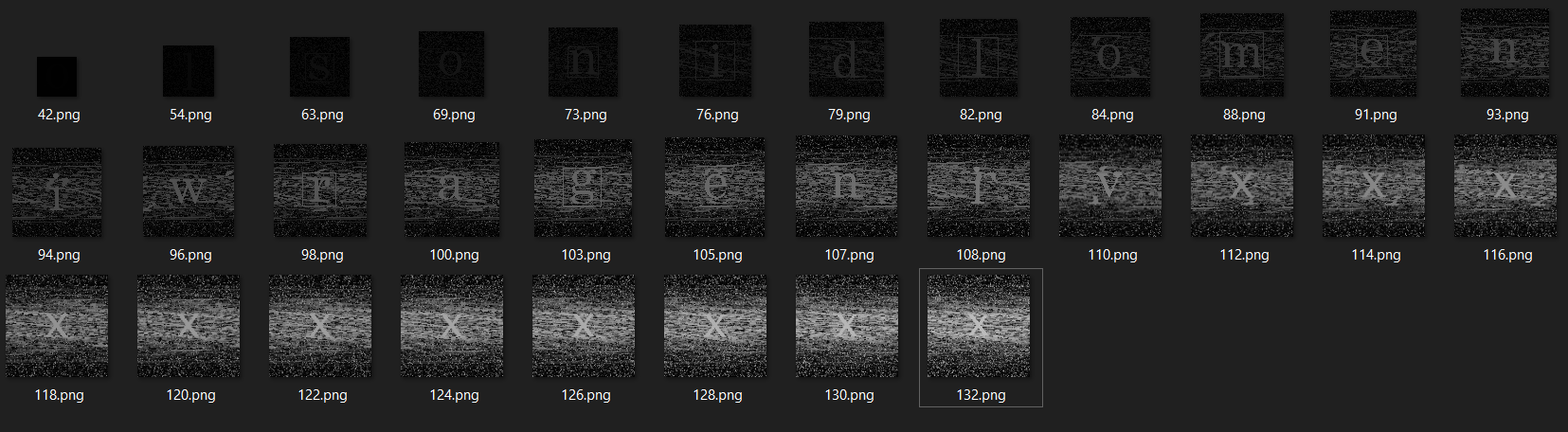
We can see from the images that a different letter is appearing after 110.png. Not so clear, though.
1 | from PIL import Image |
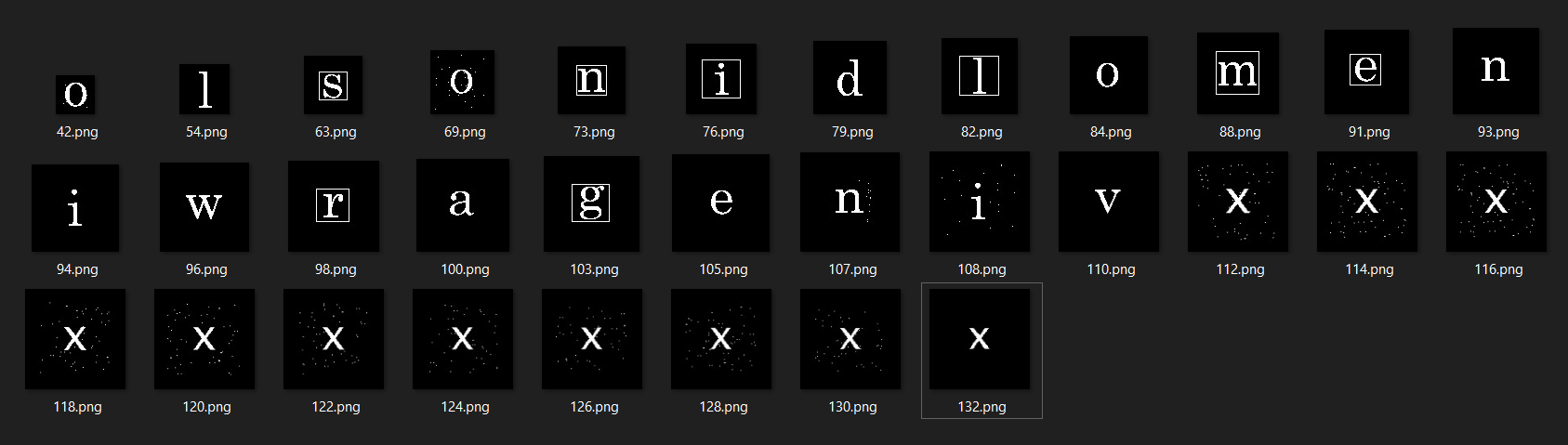
Seems that letters with a box should be the answer. Try snilmerg.html. Doesn't work.
Oh right! Letters should be aligned in the order as they appear. For example, 103.png appears before 98.png. So letter "g" should be before letter "r". Hence, gremlins.html.
#Final words
So, that's it. Wow, what a journey! I've learnt so much from it, image processing, http requesting, file structure, etc. I'll definitely tell my friends learning python or even mastering in python to take a shot. LOL.
And one last thing, I'm gonna solve level 32, definitely, in a while. ^.^